CI/CD
Настройка
CI/CD - это одна из DevOps - практик, методология разработки и набор практик, при которых в код вносятся небольшие изменения с частыми коммитами.
С технической точки зрения, цель CI — обеспечить последовательный и автоматизированный способ сборки, упаковки и тестирования приложений. При налаженном процессе непрерывной интеграции разработчики с большей вероятностью будут делать частые коммиты, что, в свою очередь, будет способствовать улучшению коммуникации и повышению качества программного обеспечения.
*Более подробную информацию вы можете посмотреть в технической документации.
Подготовка для работы в нашем случае состоит из нескольких этапов:
1. Создаем репозиторий в Gitlab;
2. Регистрируем и настраиваем бегуна в настройках CI/CD;
3. Создаем файл .gitlab-ci.yml;
Runners
Runner, он же бегун, представляет из себя рабочего, который берет на себя выполнение программы сборки, тестирования и любой другой, которую мы напишем.
Есть два вида бегунов - групповые и конкретные. Более подробно о них, а также о более развернутой конфигурации, советуем ознакомиться здесь.
Для того, чтобы зарегистрировать бегуна, нам необходимо в консоли прописать команду
$ gitlab-runner registryПосле чего поэтапно нам предложат заполнить поля:
Первым мы вводим ссылку, которую копируем из поля информации о бегунах (см. второй скрин);
Далее вводим токен, он расположен ниже ссылки;
После можем заполнить описание бегуна;
Поле tag можно оставить пустым, к нему мы вернемся чуть позже;
Далее нам предложат выбрать конфигурацию, по которой будет работать бегун, пропишем docker;
В последнем поле нужно задать значение image. Его можно прописывать и файле будущей программы (этот пример рассмотрим позже), но лучше будет прописывать это заранее. Поэтому мы укажем asciidoctor/docker-asciidoctor.
INFO
Некоторые моменты могут показаться Вам непонятными. На данный момент мы разобрали самую простую настройку бегуна, который понадобиться нам для будущей работы. Все основные вопросы мы разберем по ходу работы. Просто держите в голове ту информацию, с которой Вы только что ознакомились.
Файл для работы
С созданием репозитория всё довольно просто. После этого создадим файл для дальнейшей работы с расширением .yml.
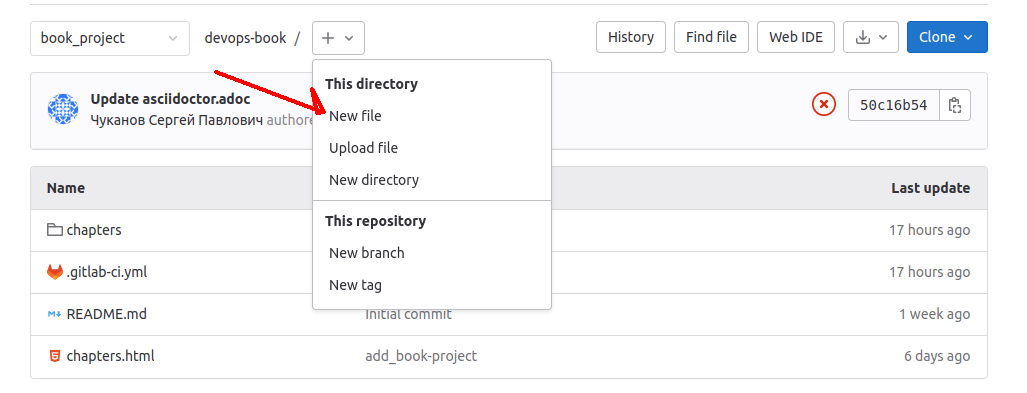

Принцип работы
Данный файл представляет из себя набор команд, значение которых мы с вами разберем. Информацию об остальных командах вы найдете здесь. То есть при каждом изменении репозитория, файл запускается и выполняет команды, с помощью которых мы взаимодействуем с вновь обновленным материалом.
Например, мы составляем методичку для обучения. Всю информацию мы храним в облаке (репозитории), загрузив всё это дело с локального компьютера. Нам нужно, чтобы при каждом обновлении облака, все файлы компилировались в один pdf-файл и html-файл, в которых будет вся информация по блокам.
Данный пример будет представлять из себя следующий командный файл:
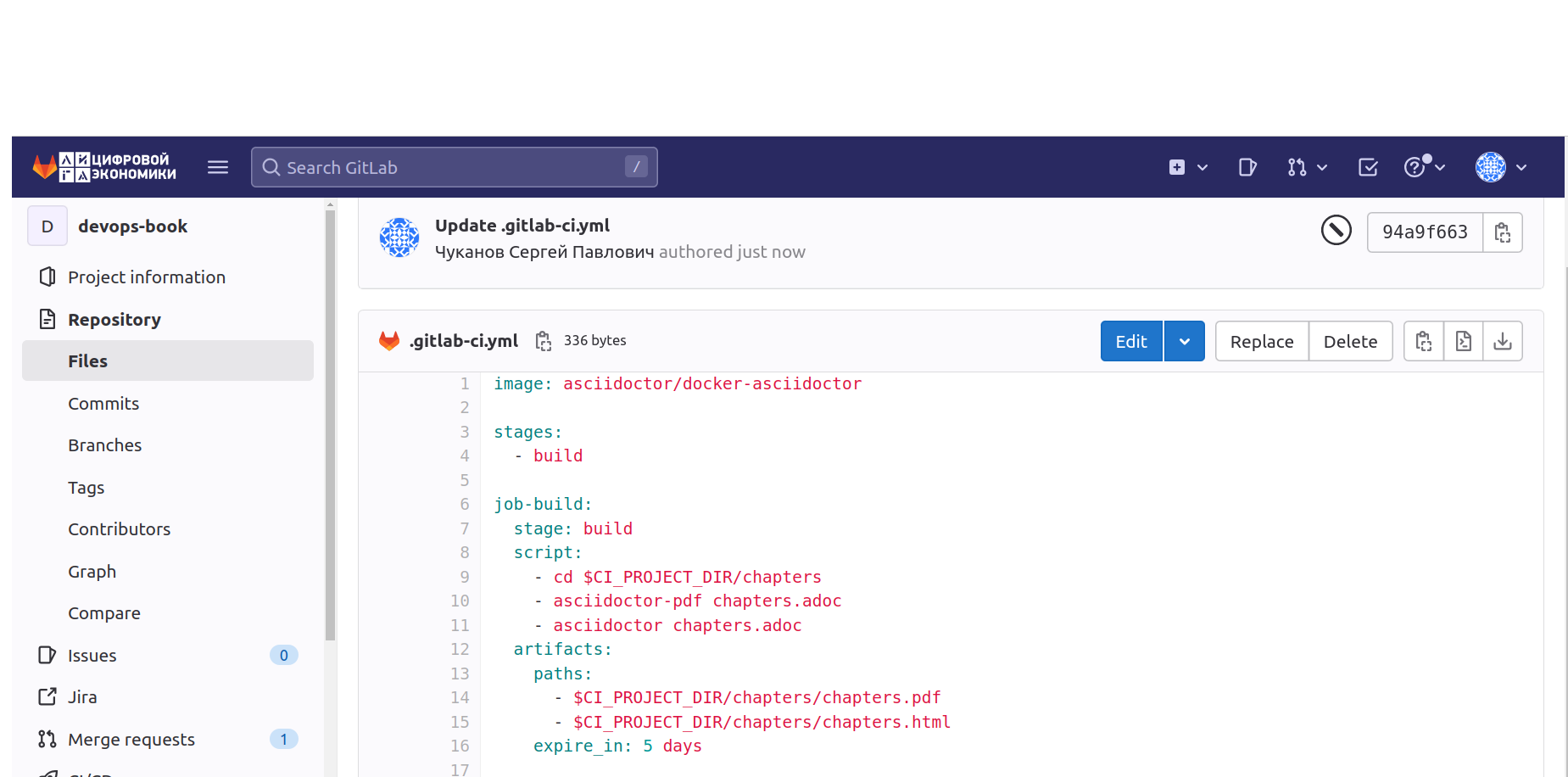
Давайте разберем, что мы здесь видим.
1. Строка image уже нам знакома, мы задали ей значение при регистрации бегуна. От её значения зависит, какие команды мы сможем с вами выполнять. Так как мы работаем в среде Docker то image задается для него, т.е какие команды нужного расширения он будет видеть.
Если мы в image запишем просто Docker, то при выполнении данного файла мы получим ошибку выполнения script: command not found.
Доступные зависимости для Docker можно на найти на https://hub.docker.com/.
2. Строка default задает конфигрурации в глобальной области видимости. Перебить эти конфиги можно, если прописать их непосредственно в самой задаче, вернемся к этому позже.
Там же мы можем задать поле tag, с которым мы уже познакомились при регистрации бегуна. Данная информация значит, что за выполнение этой работы возьмется бегун с таким же тегом.
3. Stages - это этапы, с которыми взаимодействует бегун, и в которых выполняется определенная работа над проектом. Этапов может быть несколько, в зависимости от того, что вы хотите сделать. Наименования могут быть произвольными.
WARNING
Полей JOB для одного STAGE может быть несколько. Последующий STAGE не выполнится, если один из JOB предыдущего STAGE не завершится корректно? но есть специальная команда, игнорирующая это условие. Подробнее о JOB можно ознакомиться здесь.
4. job-build - непосредственно сама работа определенного STAGE. Его мы задаем в одноименной строке.
4.1. script - процесс, который будет выполняться в job. Здесь мы прописываем консольные команды, в зависимости от результата, который хотим получить. Все эти команды работают и в терминале компьютера. Т.е. наша задача автоматизировать процесс выполнения необходимых запросов.
Данный скрипт означает, что мы переходим в папку с контентом и далее преобразуем его в один единый файл с нужным расширением. В нашем случае это PDF формат на второй строчке и HTML формат на третьей.
4.2 Artifacts - список файлов или каталогов, которые появляются в выполненном задании и которые вы сможете загрузить себе на компьютер.
4.2.1 paths - это путь, в котором будет располагаться готовый файл. Обратите внимание, что мы задали ему имя того файла, с которым происходит работа, но с другим расширением, т.е. с тем, которое ожидаем получить на выходе.
4.2.2 expire_in - команда, которая задает время храния данного артефакта.
Проверка
После того, как мы написали программу, сохраняем изменения в файле, после чего он автоматический запуститься и результат его работы мы смотрим в разделе CI/CD -> pipelines нашего репозитория.
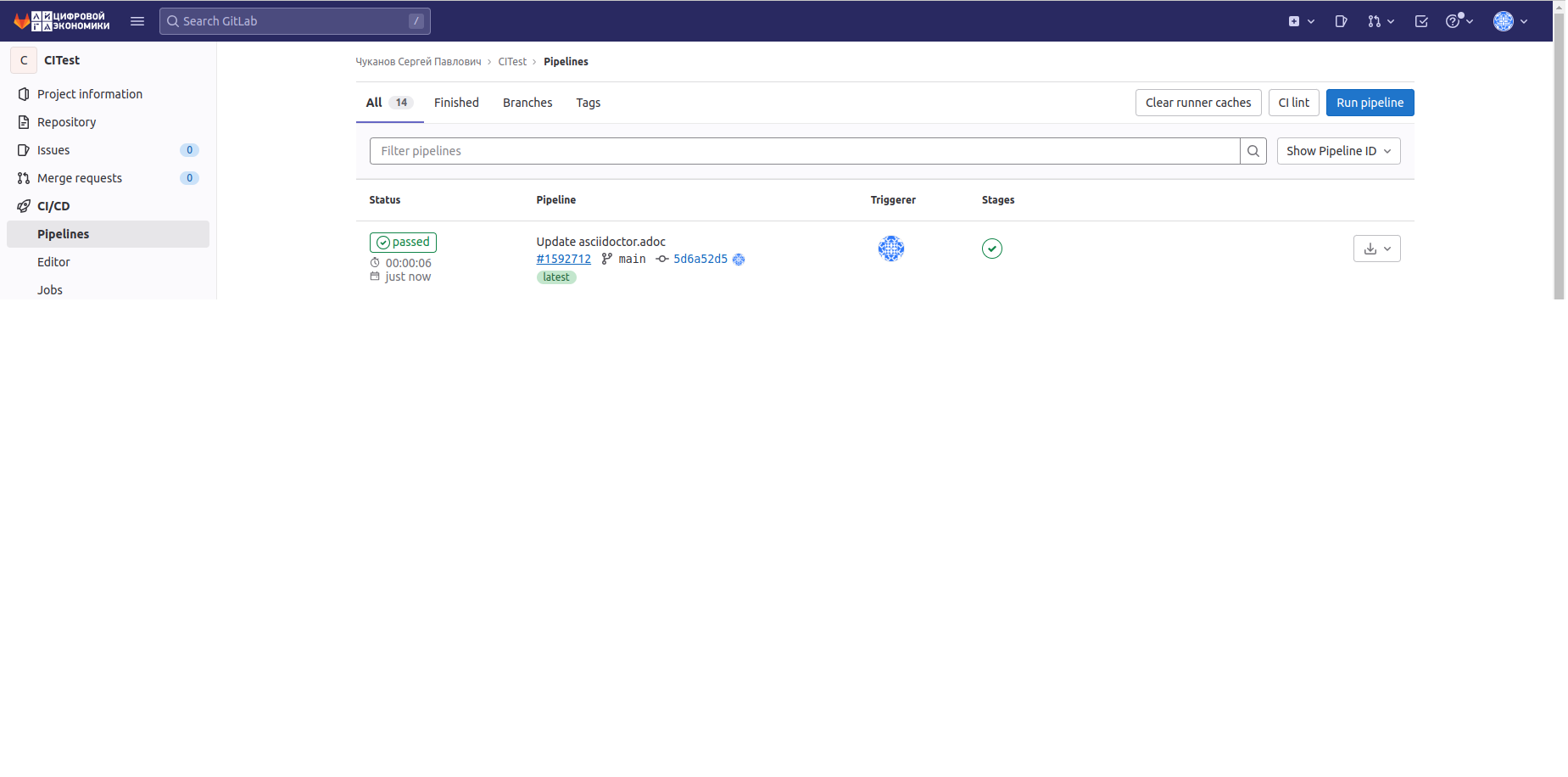
Кликнув на кнопку Passed мы откроем вкладку со STAGES и их JOB:
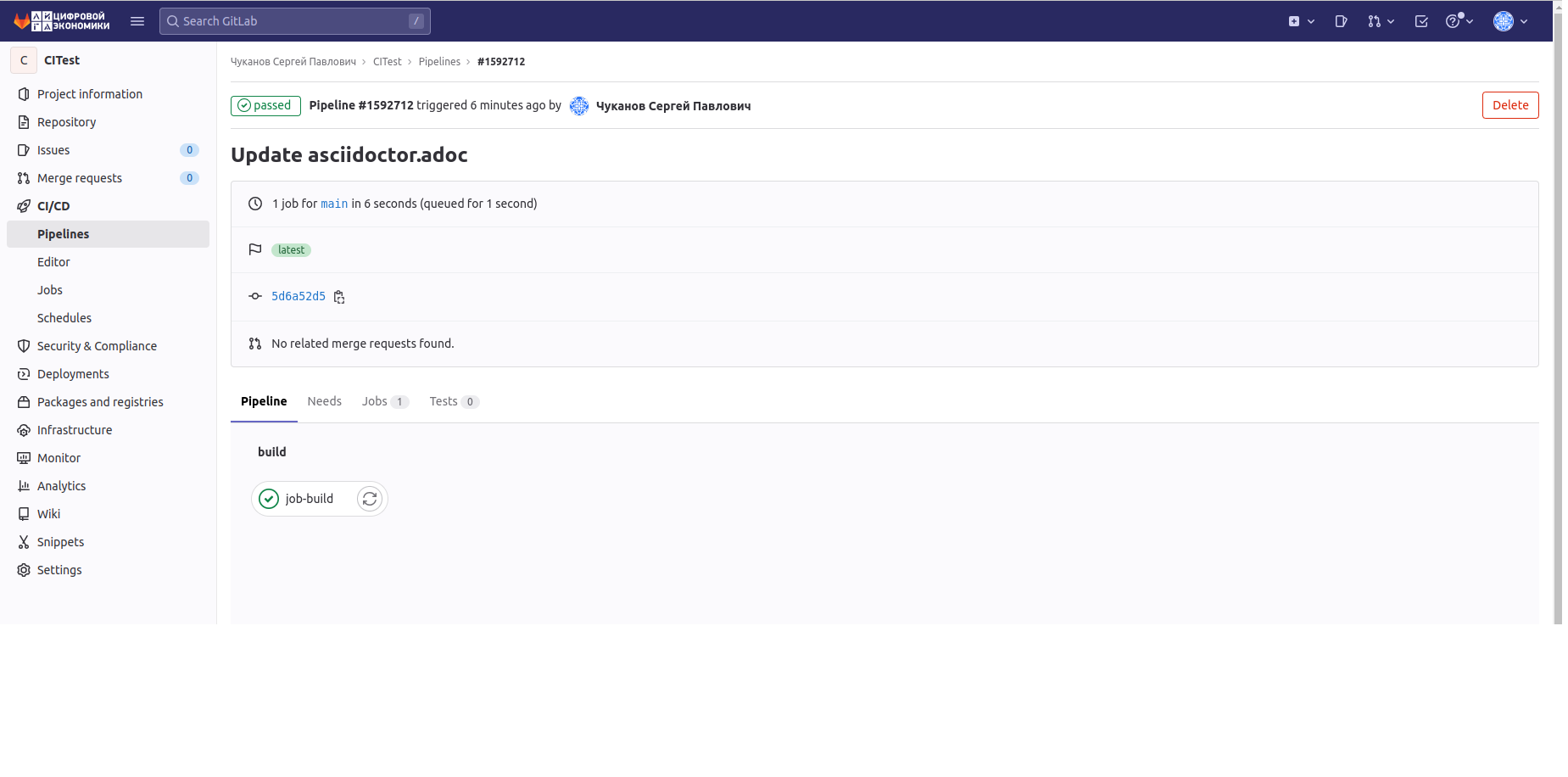
Нажмем на JOB и увидим сам код выполнения:
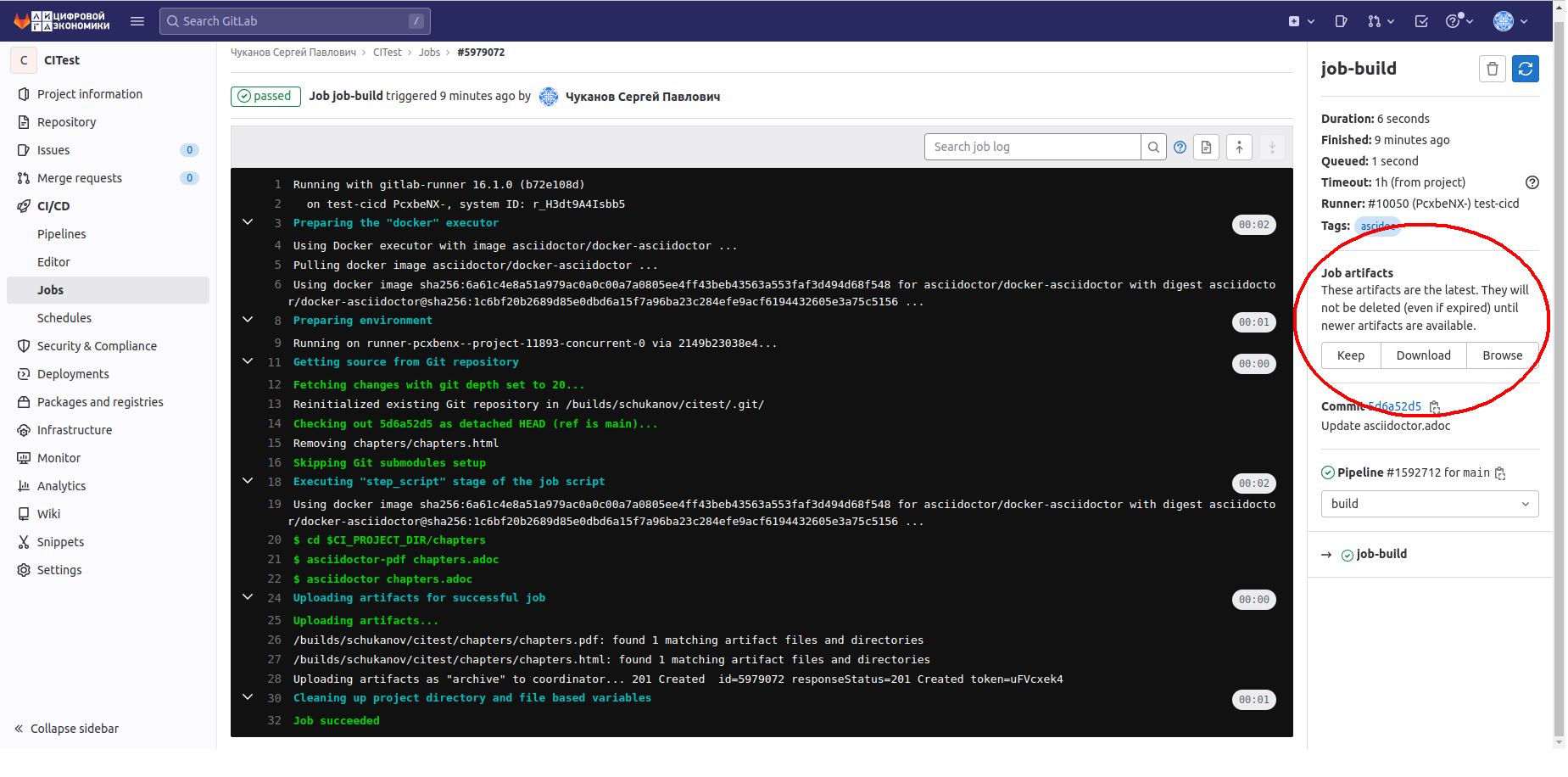
Кругом обозначены артефакты, полученные в ходе выполнения задания.